はじめに:検索が「答え」に変わる時代、あなたの羅針盤は最新ですか?
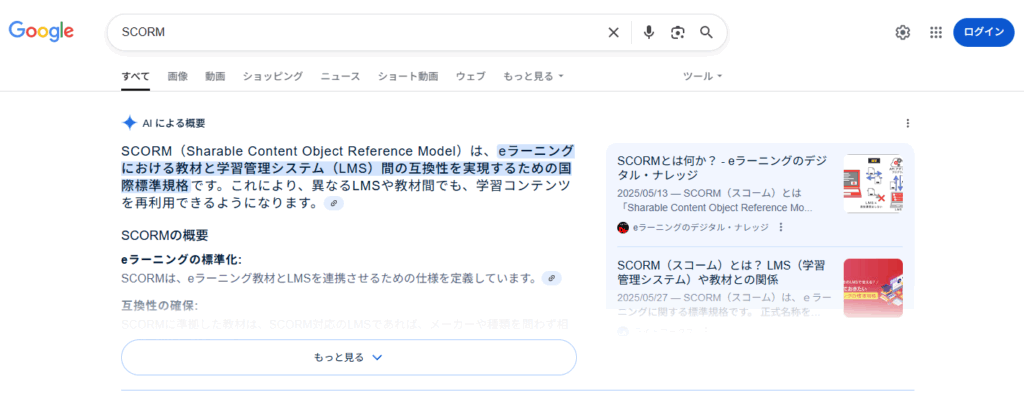
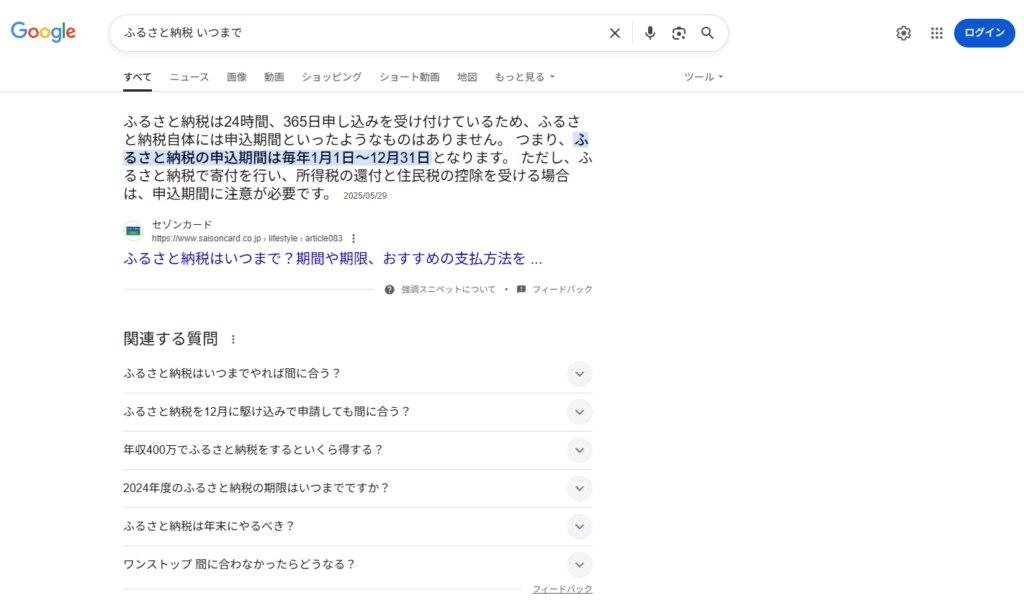
2023年以降、ChatGPTやGoogle SGE(AIオーバービュー)といった生成AIの波が、検索エンジンの世界を根底から揺るがしています。ユーザーはもはや、青いリンクの一覧から答えを「探す」のではなく、AIが生成する「答え」を直接受け取るという、全く新しい情報体験を始めています。
この地殻変動は、私たちWebマーケター、サイト運営者、そして全てのコンテンツ制作者に、重大な問いを突きつけています。
「これまで培ってきたSEOの知識は、もはや通用しないのではないか?」
この漠然とした、しかし切実な不安に応えるため、私たちはこの「生成AI時代のSEO学習シリーズ」を立ち上げました。本シリーズは、変化の激しい時代を乗りこなし、AIとユーザーの両方から選ばれる存在になるための、体系的かつ実践的な知識を提供する、新しい時代の「航海図」です。
この記事では、シリーズ全体のコンセプト、学習の進め方、そして私たちが目指すゴールについてご紹介します。
本シリーズの対象読者
本シリーズは、以下のような方を対象としています。
- 企業のWebマーケティング担当者
- オウンドメディアやブログの運営者・編集者
- SEOコンサルタント、コンテンツライター
- 自社サイトからの集客を強化したい経営者・事業責任者
基本的なSEOの知識(キーワード、内部対策、外部対策など)は持ち合わせているものの、SGEやAEO、LLMOといった新しい概念への対応に課題を感じ、知識のアップデートを求めている方を主な読者として想定しています。
シリーズの構成:3つのステップで「知識」を「実践力」へ
本シリーズは、「基礎知識編」「応用編」「実践編」の3つのステップで構成されており、順に読み進めることで、ゼロからでも体系的にAI時代のSEOを習得できるように設計されています。
1. 基礎知識編(全18本)
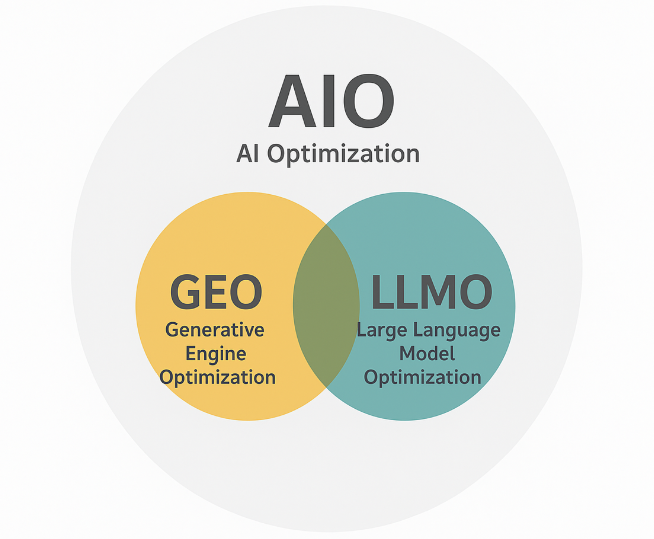
目的:変化の本質を理解し、新しい「共通言語」を学ぶ AI時代に登場した新しい概念やツールの「What(何か?)」と「Why(なぜ重要か?)」を学びます。SGE、CopilotといったAI検索の仕組みから、AEO(回答エンジン最適化)、GEO(生成エンジン最適化)、LLMO(大規模言語モデル最適化)といった新しい最適化の考え方、そしてAI時代に改めて重要となるE-E-A-Tやコンテンツ品質まで、全ての土台となる知識を固めます。
2. 応用編(全24本)
目的:明日から使える「戦略」と「技術」を身につける 基礎知識を基に、具体的な「How(どうやるか?)」を学びます。ユーザーの質問意図を捉えるキーワードリサーチ、AIに評価されるコンテンツ構成、戦略的なスキーママークアップ、サイト内外でのE-E-A-T強化策、そしてAIライティングツールの活用法まで、実務に直結する応用技術を網羅します。
3. 実践編(全22本)
目的:知識を行動に変え、「成果」を生み出す 理論を実際の業務に落とし込むための、ケーススタディやワークショップ、チェックリストを提供します。成功事例の分析を通じて「なぜ成果が出たのか」を学び、ハンズオン形式のステップガイドで具体的な作業手順を体験することで、知識を揺るぎない「実践力」へと昇華させます。
シリーズが掲げる核心的な哲学
技術や用語は変わっても、本シリーズが一貫して伝えたい哲学は非常にシンプルです。それは、「SEOの本質は、ユーザーのために最高の価値を提供し、信頼を築くことにある」という、普遍的な原則です。
AI時代のSEOとは、AIという新しいアルゴリズムをハックする小手先のテクニックではありません。むしろ、AIという「極めて優秀で、誠実さを求める読者」が登場したことで、ごまかしが一切効かなくなり、コンテンツの本質的な価値(E-E-A-T、独自性、信頼性)が、これまで以上に厳しく問われるようになったのです。
本シリーズで紹介する全ての施策は、この「ユーザーへの価値提供」と「信頼の構築」という根幹に繋がっています。
さあ、新しい時代の航海へ出発しよう
私たちは今、誰も正解を知らない、新しい検索の海の前に立っています。変化は、時に不安をもたらすかもしれません。しかし、それは同時に、本質的な価値を追求してきた者にとっては、大きなチャンスでもあります。
この「生成AI時代のSEO学習シリーズ」が、あなたの航海の信頼できる羅針盤となり、ビジネスを新たな成長へと導く一助となることを、心から願っています。
まずは、全ての始まりである「基礎知識編1:生成AI時代のSEOとは何か」から、あなたの新しい学びをスタートさせてください。